Stock relocation solution
The client was faced with the challenge of creating an optimal assortment list for more than 2,000 drugstores located in 30 different regions. They turned to us for a solution. We used a mathematical model and AI algorithms that considered location, housing density and proximity to key locations to determine an optimal assortment list for each store. By integrating with POS terminals, we were able to improve sales and help the client to streamline its product offerings.

Client Identification
The client wanted to provide the highest quality service to its customers. To achieve this, they needed to find the best way to collect information about customer preferences and build an optimal tracking system for customer behavior. To solve this challenge, we built a recommendation and customer behavior tracking system using advanced analytics, Face Recognition, Computer Vision, and AI technologies. This system helped the club staff to build customer loyalty and create a top-notch experience for their customers.


Performance Measurement
The Retail company struggled with controlling sales and monitoring employees’ performance. We implemented a software solution that tracks sales, customer service, and employee performance in real-time. The system also provides recommendations for improvements, helping the company increase profits and improve customer service.


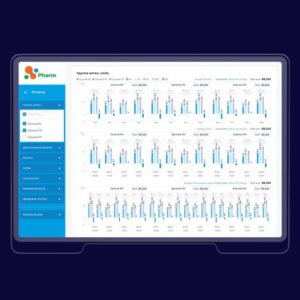
Supply chain dashboard
The client needed to optimize the work of employees by building a data source integration and reporting system to use at different management levels. Ultimately, we developed a system that unifies relevant data from all sources and stores them in a structured form, which saves more than 900 hours of manual work monthly.